Create a Prompt
Prerequisites
- An OpenAI API key or an Azure OpenAI key.
- A project that meets the criteria noted below.
Model provider API keys
You can specify one OpenAI API key and/or multiple Azure OpenAI keys per organization. Keys only need to be added once.
Click API Keys in the top right of the Prompts page to open the Model Provider API Keys window:

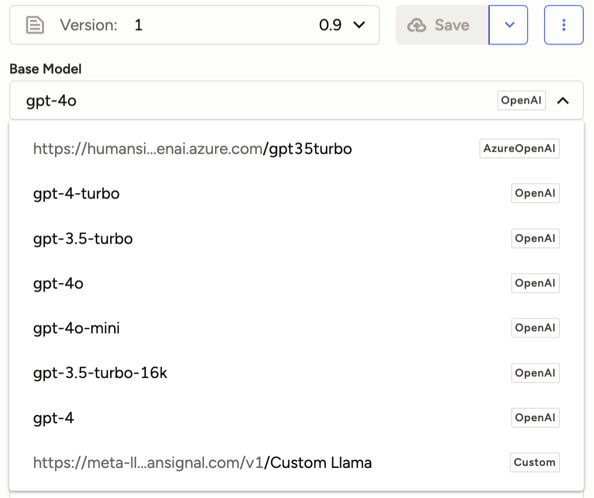
Once added, you will have the option to select from the base models associated with each API key as you configure your prompts:
To remove the key, click API Keys in the upper right of the Prompts page. You’ll have the option to remove the key and add a new one.
Add OpenAI, Azure OpenAI, or a custom model
Use an OpenAI key
You can only have one OpenAI key per organization. For a list of the OpenAI models we support, see Features, requirements, and constraints.
If you don’t already have one, you can create an OpenAI account here.
You can find your OpenAI API key on the API key page.
Once added, all supported OpenAI models will appear in the base model options when you configure your prompt.
Use an Azure OpenAI key
Each Azure OpenAI key is tied to a specific deployment, and each deployment comprises a single OpenAI model. So if you want to use multiple models through Azure, you will need to create a deployment for each model and then add each key to Label Studio.
For a list of the Azure OpenAI models we support, see Features, requirements, and constraints.
To use Azure OpenAI, you must first create the Azure OpenAI resource and then a model deployment:
- From the Azure portal, create an Azure OpenAI resource.
note
If you are restricting network access to your resource, you will need to add the following IP addresses when configuring network security:
- 3.219.3.197
- 34.237.73.3
- 44.216.17.242
- From Azure OpenAI Studio, create a deployment. This is a base model endpoint.
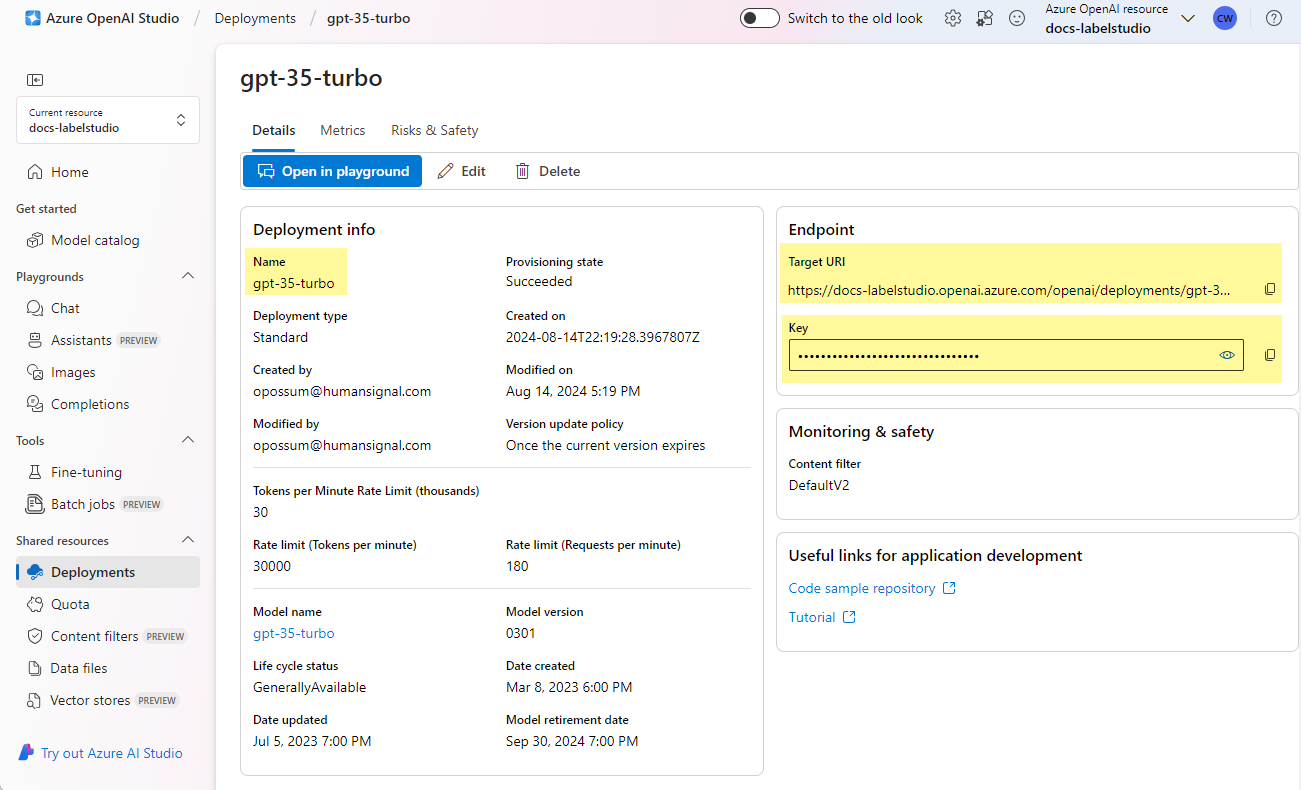
When adding the key to Label Studio, you are asked for the following information:
| Field | Description |
|---|---|
| Deployment | The is the name of the deployment. By default, this is the same as the model name, but you can customize it when you create the deployment. If they are different, you must use the deployment name and not the underlying model name. |
| Endpoint | This is the target URI provided by Azure. |
| API key | This is the key provided by Azure. |
You can find all this information in the Details section of the deployment in Azure OpenAI Studio.
Use a custom LLM
You can use your own self-hosted and fine-tuned model as long as it meets the following criteria:
- Your server must provide JSON mode for the LLM.
- The server API must follow OpenAI format.
Examples of compatible LLMs include Ollama and sglang.
To add a custom model, enter the following:
- A name for the model.
- The endpoint URL for the model. For example,
https://my.openai.endpoint.com/v1 - An API key to access the model. (Optional)
- An auth token to access the model. (Optional)
Create a Prompt
From the Prompts page, click Create Prompt in the upper right and then complete the following fields:
| Name | Enter a name for the Prompt. |
| Description | Enter a description for the Prompt. |
| Type | Select the Prompt model type: Text Classification or Named Entity Recognition |
| Target Project | Select the project you want to use. If you don’t have any eligible projects, you will see an error message. See the note below. |
| Classes | This list is automatically generated from the labeling configuration of the target project. |
Eligible projects
Target projects must meet the following criteria:
- The labeling configuration for the project must be compatible with the Type you selected above:
- For text classification, this means that the labeling configuration for the project must use
Choicetags. - For NER, this means that the labeling configuration for the project must use
Labeltags. - The project must have one output type (
ChoiceorLabel) and not a mix of both. - The project must include text data. While it can include other data types such as images or video, it must include
<Text>. - You must have access to the project. If you are in the Manager role, you need to be added to the project to have access.
- The project cannot be located in your Personal Sandbox workspace.
- While projects connected to an ML backend will still appear in the list of eligible projects, we do not recommend using Prompts with an ML backend.
Types
Text classification
Text classification is the process of assigning predefined categories or labels to segments of text based on their content. This involves analyzing the text and determining which category or label best describes its subject, sentiment, or purpose. The goal is to organize and categorize textual data in a way that makes it easier to analyze, search, and utilize.
Text classification labeling tasks are fundamental in many applications, enabling efficient data organization, improving searchability, and providing valuable insights through data analysis. Some examples include:
- Spam Detection: Classifying emails as “spam” or “ham” (not spam).
- Sentiment Analysis: Categorizing user reviews as “positive,” “negative,” or “neutral.”
- Topic Categorization: Assigning articles to categories like “politics,” “sports,” “technology,” etc.
- Support Ticket Classification: Labeling customer support tickets based on the issue type, such as “billing,” “technical support,” or “account management.”
- Content Moderation: Identifying and labeling inappropriate content on social media platforms, such as “offensive language,” “hate speech,” or “harassment.”
Named entity recognition (NER)
A Named Entity Recognition (NER) labeling task involves identifying and classifying named entities within text. For example, people, organizations, locations, dates, and other proper nouns. The goal is to label these entities with predefined categories that make the text easier to analyze and understand. NER is commonly used in tasks like information extraction, text summarization, and content classification.
For example, in the sentence “Heidi Opossum goes grocery shopping at Aldi in Miami” the NER task would involve identifying “Aldi” as a place or organization, “Heidi Opossum” as a person (even though, to be precise, she is an iconic opossum), and “Miami” as a location. Once labeled, this structured data can be used for various purposes such as improving search functionality, organizing information, or training machine learning models for more complex natural language processing tasks.
NER labeling is crucial for industries such as finance, healthcare, and legal services, where accurate entity identification helps in extracting key information from large amounts of text, improving decision-making, and automating workflows.
Some examples include:
- News and Media Monitoring: Media organizations use NER to automatically tag and categorize entities such as people, organizations, and locations in news articles. This helps in organizing news content, enabling efficient search and retrieval, and generating summaries or reports.
- Intelligence and Risk Analysis: By extracting entities such as personal names, organizations, IP addresses, and financial transactions from suspicious activity reports or communications, organizations can better assess risks and detect fraud or criminal activity.
- Specialized Document Review: Once trained, NER can help extract industry-specific key entities for better document review, searching, and classification.
- Customer Feedback and Product Review: Extract named entities like product names, companies, or services from customer feedback or reviews. This allows businesses to categorize and analyze feedback based on specific products, people, or regions, helping them make data-driven improvements.